Tristan Colgate-McFarlane



Using Seasonality in Prometheus alerting (Qubit Eng Blog)
Note: This was originally posted on the Qubit Engineering Blog, and CopyRight is, at the time of writing, owned by Coveo. It was written, and illustrated, by me, but would have been unreadable but for input and editing by my fantastic teammates.
In this post, we will show a worked example of building a Prometheus alert for a typical user facing service.
Introduction
At Qubit we have recently completely
a migration from our legacy Shinken and Graphite based monitoring to a system built around Prometheus, a modern time series database.
Prometheus has many features that are particularly well suited to our current infrastructure. To pick a few at random,
- Works well in containerized environments.
- Exporters are easy to write, and the existing client libraries are pleasant to use.
- It was easy to get started, and has proved very adaptable to out more extreme use cases.
One of its most appealing features is the rich query language. Once you are over the initial learning curve, a world of possibilities awaits.
Living with your errors.
In high traffic environments, traditional check and threshold based alerting begins to cause pain. Errors are a simple fact of life. For clients traversing the internet, especially mobile clients, possibly travelling at high speed through rolling green hills, timeouts are unavoidable. Anyone with a server directly connected to the Internet will know that not everyone is polite enough to send you perfectly formed HTTP request of the kind you intended to receive. As scale increases, failures within your infrastructure eventually become equally unavoidable.
If we have to live with a background of alerts, we need methods for determining when we should be worried, and when we should not. Fortunately statisticians have been hard at work for a great many year,creating the mathematical tools we need to achieve just that.
Imagine a simple service receiving traffic from the internet. If we have a consistent rate of events, spotting anomalies should not be too difficult. We could assume our traffic will remain within a fixed margin of this, and alert when levels go below or above the average level of traffic we have seen recently.
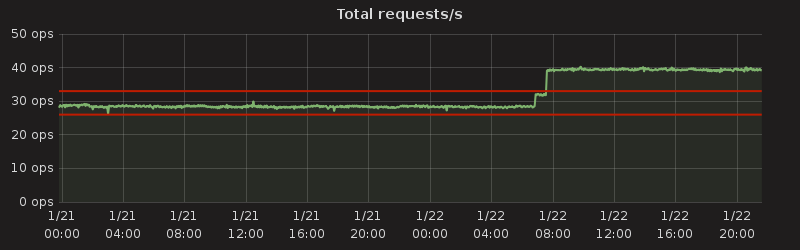
Unfortunately, any service interacting with humans will be very unlikely to see traffic like this. Traffic isolated to one country will often show a “Camels Hump” shape. Working out why you traffic is the shape it is can be fun, and quite enlightening.
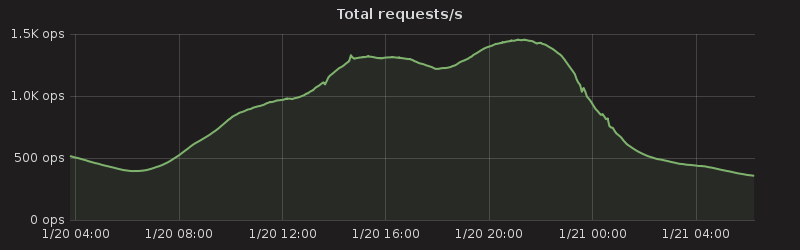
On a global scale things do even out a little, but humans are not evenly distributed across the planet (distribution of land, and distribution of wealth over the surface of the earth have seen to that). People will talk of traffic following the sun, with peaks of traffic as each major region comes on line.
These factors make it hard for simple threshold based alerting to work. We cannot merely give a minimum and maximum level. No one set of thresholds will work reliably throughout the entire day.
The Changing Seasons
Rather than ask what the level of traffic is with respect to previous traffic today, we can instead ask if our expected traffic at this time is reasonable relative to some previous point in time that we expect to have approximately the same traffic levels. In statistics, this is termed “Seasonality”. In much the same way that we consider the weather in winter to to be similar from year to year, we can find the same similarity between traffic levels in our system over different time ranges.
The obvious choice is to compare our traffic today with our traffic 24 hours ago. We can do this in Prometheus using the offset keyword. Let us assume we have a rule in place to create an aggregate of our average per-second rate of events of the previous hour.
task:events:rate1h = rate(events[1h])
job:events:rate1h =
sum by (job) (task:events:rate1h)
We could create a rule to track the rate of events from yesterday, as follows.:
job:events:offset1d_rate1h = job:events:rate1h offset 1d
This can be very useful indeed, and give you a very quick “at a glance” indication if things are more or less at the right levels. We could now monitor the difference between our current rate of events, and the previous days, and perhaps pick a simple threshold again.
However, things become more interesting if we take several offsets and collect them together. In Prometheus we can achieve this with the following rule.
job_offset:events:offset_rate1h{offset="1d"} =
job:events:rate1h offset 1d
job_offset:events:offset_rate1h{offset="2d"} =
job:events:rate1h offset 2d
job_offset:events:offset_rate1h{offset="3d"} =
job:events:rate1h offset 3d
Building up these historical views of our data can become quite mesmerizing. But beyond produce pretty graphs, we can put this to more direct use. If each days samples are similar, we can do the following.
- Take the average of the rates of events for each of our previous days
- Calculate the Standard Deviation between the previous days rates of events
Standard deviation gives us a measure of how much we can expect other days to vary from the 3 days worth of samples we have.[a][b] We can the calculate upper and lower bounds for what is reasonable to expect, and alert if we move beyond those levels.
Effectively we are dynamically creating our thresholds. In Prometheus we do this as follows:
job:events:avg_offset_rate1h =
avg without (offset) (job_offset:events:offset_rate1h)
job:events:stddev_offset_rate1h =
stddev without (offset) (job_offset:events:offset_rate1h)
job:events:normalised_offset_rate1h =
(job:events:rate1h - job:events:avg_offset_rate1h) /
job:events:stddev_offset_rate1h
And finally we create an alert to inform us when we’ve moved beyond our threshold. We will suggest that if our traffic is between, ±3 standard[c][d] deviations from our previous levels things are looking fine. If we move outside of those levels, we will raise an alert.
Note: Whether or not this is reliable enough to be considered worthy of paging someone is really down to your particular levels and shape of traffic.
ALERT EventLevelUnexecpted
IF abs(job:events:normalised_offset_rate1h) > 3
FOR 1h
LABELS { severity = "medium" }
ANNOTATIONS {
description = "Arrival of events is out by {{ $value }} standard deviations",
}
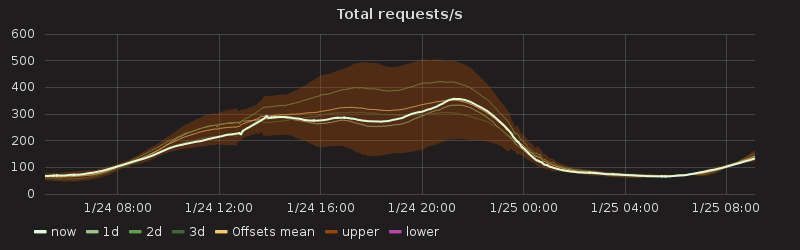
What is normal?
If the underlying data samples conform to a normal distribution ,3 standard deviations would suggest a 99.7% chance that we are experiencing a problem. In reality this is unlikely to be the case, but may be a reasonable estimation.
More traffic sample can help us tighten the our prediction. There is a further problem however. Just as our morning traffic and evening traffic are different, there are likely to be similar differences between individual days.If our weekend traffic differs in volume or shape from our weekday traffic, our calculation are off. Our alerts are likely to fire on Saturday, and fail to fire on a Monday morning. (This is caused by our sample points not actually being from a normal distribution.) We may see more correlation if we choose similar hours in each week, rather than simply each day.
One limitation you may run into with Prometheus, if trying to extend too far into the past, is with its retention periods. Prometheus is designed for alerting rather than data mining. The default retention period is 2 weeks. In very dynamic Environments it is often necessary to reduce this further.
This would seem to limit the historical series we can query, but we can perform a simple trick to “remember”, the old data for a specific set of queries.
job_offset:events:offset_rate1h{offset="1w"} =
job:events:rate1h offset 1w
job_offset:events:offset_rate1h{offset="2w"} =
job_offset:events:offset_rate1h{offset="1w"} offset 1w
job_offset:events:offset_rate1h{offset="3w"} =
job_offset:events:offset_rate1h{offset="2w"} offset 1w
This way, we can now produce an estimate based on 3 values of the last 3 weeks, even though our server may only actually hold 8 days worth of data. It is important to note that you should not mix these 1w samples in with your 1d samples above. The avg and stddev rules from above should be adjusted, perhaps as follows:
job:events:avg_offset1d_rate1h = avg without (offset) (job_offset:events:offset_rate1h{offset=~".d"})
job:events:avg_offset1w_rate1h = avg without (offset) (job_offset:events:offset_rate1h{offset=~".w"})
job:events:stddev_offset1d_rate1h = stddev without (offset) (job_offset:events:offset_rate1h{offset=~".d"})
job:events:stddev_offset1w_rate1h = stddev without (offset) (job_offset:events:offset_rate1h{offset=~".w"})
Alternatively we could store these with as one metric with a label. Adjusting the final calculation and alert are left as an educational exercise for the Reader.
Conclusion
Prometheus provides a powerful set of tools to help up build alerts based on a deeper understanding of our data than simple thresholds. This post has explored one such technique.
For those interested in more on this topic, I highly recommend this video (and the related Better Living Through Statistics talks), by Jamie Wilkinson, and his excellent contributions to O’Reilly’s Site Reliability Engineering book.
Those interested in a more rigorous discussion of the maths can find many great books to choose from, but could do worse than Statistics in a Nutshell
Look out for future posts discussing how we’re leveraging Prometheus at Qubit